4.4 KiB
6.9 分布式爬虫
互联网时代的信息爆炸是很多人倍感头痛的问题,应接不暇的新闻、信息、视频,无孔不入地侵占着我们的碎片时间。但另一方面,在我们真正需要数据的时候,却感觉数据并不是那么容易获取的。比如我们想要分析现在人在讨论些什么,关心些什么。甚至有时候,可能我们只是暂时没有时间去一一阅览心仪的小说,但又想能用技术手段把它们存在自己的资料库里。哪怕是几个月或一年后再来回顾。再或者我们想要把互联网上这些稍纵即逝的有用信息保存起来,例如某个非常小的论坛中聚集的同好们的高质量讨论,在未来某个时刻,即使这些小众的聚集区无以为继时,依然能让我们从硬盘中翻出当初珍贵的观点来。
除去情怀需求,互联网上有大量珍贵的开放资料,近年来深度学习如雨后春笋一般火热起来,但机器学习很多时候并不是苦于我的模型是否建立得合适,我的参数是否调整得正确,而是苦于最初的起步阶段:没有数据。
作为收集数据的前置工作,有能力去写一个简单的或者复杂的爬虫,对于我们来说依然非常重要。
基于 colly 的单机爬虫
有很多程序员比较喜欢在 v2ex 上讨论问题,发表观点,有时候可能懒癌发作,我们希望能直接命令行爬到 v2ex 在 Go tag 下的新贴,只要简单写一个爬虫即可。
《Go 语言编程》一书给出了简单的爬虫示例,经过了多年的发展,现在使用 Go 语言写一个网站的爬虫要更加方便,比如用 colly 来实现爬取 v2ex 前十页内容:
package main
import (
"fmt"
"regexp"
"time"
"github.com/gocolly/colly"
)
var visited = map[string]bool{}
func main() {
// Instantiate default collector
c := colly.NewCollector(
colly.AllowedDomains("www.v2ex.com"),
colly.MaxDepth(1),
)
detailRegex, _ := regexp.Compile(`/go/go\?p=\d+$`)
listRegex, _ := regexp.Compile(`/t/\d+#\w+`)
// On every a element which has href attribute call callback
c.OnHTML("a[href]", func(e *colly.HTMLElement) {
link := e.Attr("href")
// 已访问过的详情页或列表页,跳过
if visited[link] && (detailRegex.Match([]byte(link)) || listRegex.Match([]byte(link))) {
return
}
// 匹配下列两种 url 模式的,才去 visit
// https://www.v2ex.com/go/go?p=2
// https://www.v2ex.com/t/472945#reply3
if !detailRegex.Match([]byte(link)) && !listRegex.Match([]byte(link)) {
println("not match", link)
return
}
time.Sleep(time.Second)
println("match", link)
visited[link] = true
time.Sleep(time.Millisecond * 2)
c.Visit(e.Request.AbsoluteURL(link))
})
// Before making a request
c.OnRequest(func(r *colly.Request) {
/*
r.Headers.Set("Cookie", "")
r.Headers.Set("DNT", "1")
r.Headers.Set("User-Agent", "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36")
r.Headers.Set("Host", "www.v2ex.com")
*/
})
err := c.Visit("https://www.v2ex.com/go/go")
if err != nil {
fmt.Println(err)
}
}
分布式爬虫
想像一下,你们的信息分析系统运行非常之快。获取信息的速度成为了瓶颈,虽然可以用上 Go 语言所有优秀的并发特性,将单机的 CPU 和网络带宽都用满,但还是希望能够加快爬虫的爬取速度。在很多场景下,速度是有意义的:
- 对于价格战期间的电商们来说,希望能够在对手价格变动后第一时间获取到其最新价格,再靠机器自动调整本家的商品价格。
- 对于类似头条之类的 feed 流业务,信息的时效性也非常重要。如果我们慢吞吞地爬到的新闻是昨天的新闻,那对于用户来说就没有任何意义。
所以我们需要分布式爬虫。从本质上来讲,分布式爬虫是一套任务分发和执行系统。而常见的任务分发,因为上下游存在速度不匹配问题,必然要借助消息队列。
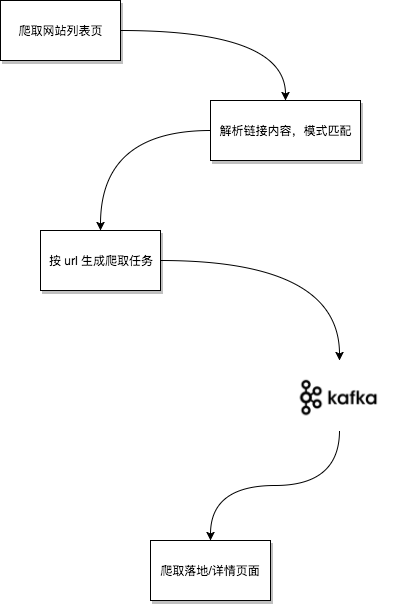
上游的主要工作是根据预先配置好的起点来爬取所有的目标“列表页”。